Continued from Part 1 — From No Outbound, No Meetings to a Target You Can Trust
If you missed Part 1, we covered why outbound was dead (AEs not prospecting), why ZoomInfo/Apollo dumps failed (titles ≠ roles, no post-sale signal), a quick glossary (telematics, DTCs, OTA, recall KPIs), and the persona graph + scoring rubric that define a true ICP for post-sale quality.
We started on a Monday with a CRM full of names and no direction. I told the team, “By Friday, your AEs will know exactly who to call and what to say.” They laughed—politely.
What is RAG?
RAG = Retrieval-Augmented Generation.
Retrieval-Augmented Generation (RAG) is a simple idea: don’t make the model guess—give it the right notes first. You store your trusted knowledge (playbooks, rules, examples) in a searchable “vector” index; at run time, the system retrieves the few most relevant snippets for a query (e.g., a contact’s title), inserts them into the prompt, and the model generates an answer using that context. The result is sharper, more consistent outputs that you can update by editing the source docs—no retraining. RAG improves accuracy, reduces hallucinations, and makes decisions explainable because you can show exactly which snippets informed the result.
Day 1: Give the model a brain.
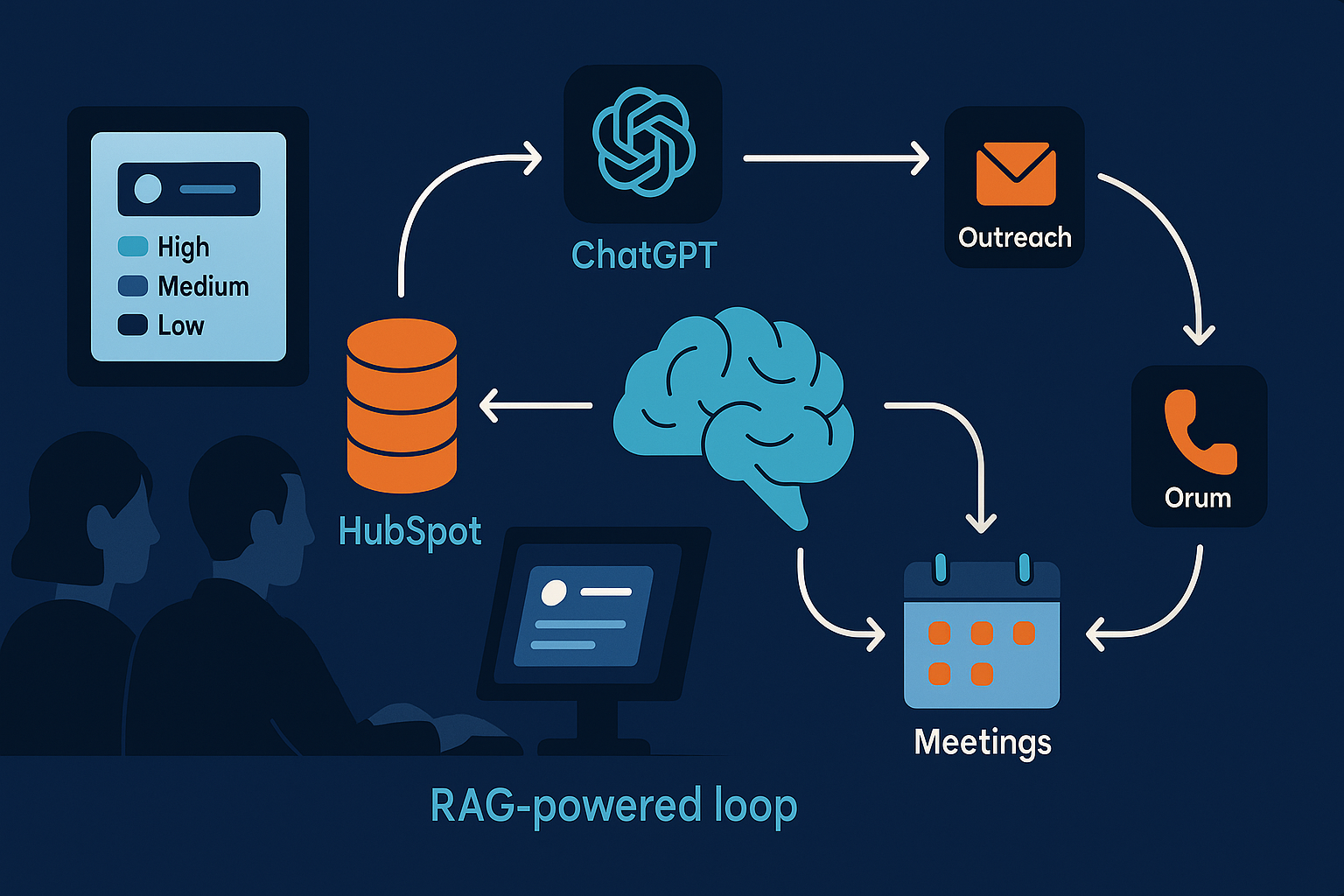
We turned tribal notes from Part 1 into a tiny knowledge base. That’s RAG—retrieval-augmented generation: don’t make the model guess; hand it the right notes first. When a contact lands, the system pulls the most relevant snippets (“Field Quality Manager → 100,” “Supplier QE → 50”) and whispers them to the model before it scores.
Day 2: Wire the loop.
HubSpot is the trigger. A contact is created or a title changes—click. The Classifier Agent fetches snippets, returns score + one-line rationale. HubSpot adds ABM points → Lead Score. If it clears the bar, Outreach enrolls the sequence; Orum queues the calls. No pep talks—AEs open a queue with High, the why, and a persona-fit opener.
Day 3: Arm the spear.
We led with the After-Sales Quality study (grounded in ~5,000 recalls & 30,000 complaints). For High-fit personas the line was simple: “Flag issues in days, not months; shrink campaign scope; verify fixes VIN-by-VIN.”
Day 4: First dials feel different.
The queue isn’t “anyone with quality in the title.” It’s Warranty, Field Quality, OTA, Connected-Vehicle owners. One record reads: “Medium—Launch Quality (upstream). Nurture.” Next: “High—Warranty Analytics (post-sale owner). Call now.” Doubt leaves the room.
Day 5: The turn.
By Friday, the company booked its first cold meetings ever. “We’re building in-house” stopped ending calls. We invited a benchmark instead: “Bring one recent field issue or OTA release. In 20 minutes we’ll show how our anomaly signatures would’ve surfaced it earlier and reduced the campaign footprint.” Now the conversation was technical, concrete, winnable.
Why it worked (the quiet mechanics)
- RAG kept us honest. The agent retrieved our rules from Part 1 every time—no drift.
- Explainability built trust. Reps saw score + rationale and could improve it; overrides fed the brain weekly.
- Message matched persona. Warranty got cost/campaign math; OTA got regression detection & post-fix verification; Regulatory got lead-time and closure assurance.
Previously: Part 1 — From No Outbound, No Meetings to a Target You Can Trust
Next: I’ll publish the prompt pack + HubSpot property schema + sample classifier function you can copy/paste.

